LLMs are increasingly evaluated on coding and reasoning tasks, yet existing benchmarks primarily measure memorised knowledge — not the ability to learn. Per Google DeepMind's cognitive framework, learning is the ability to acquire new knowledge or skills through experience, study, or instruction. Current evaluations cannot distinguish a model that truly learns from one that merely recalls.
Without benchmarks that isolate learning from recall, progress toward AGI cannot be meaningfully measured.
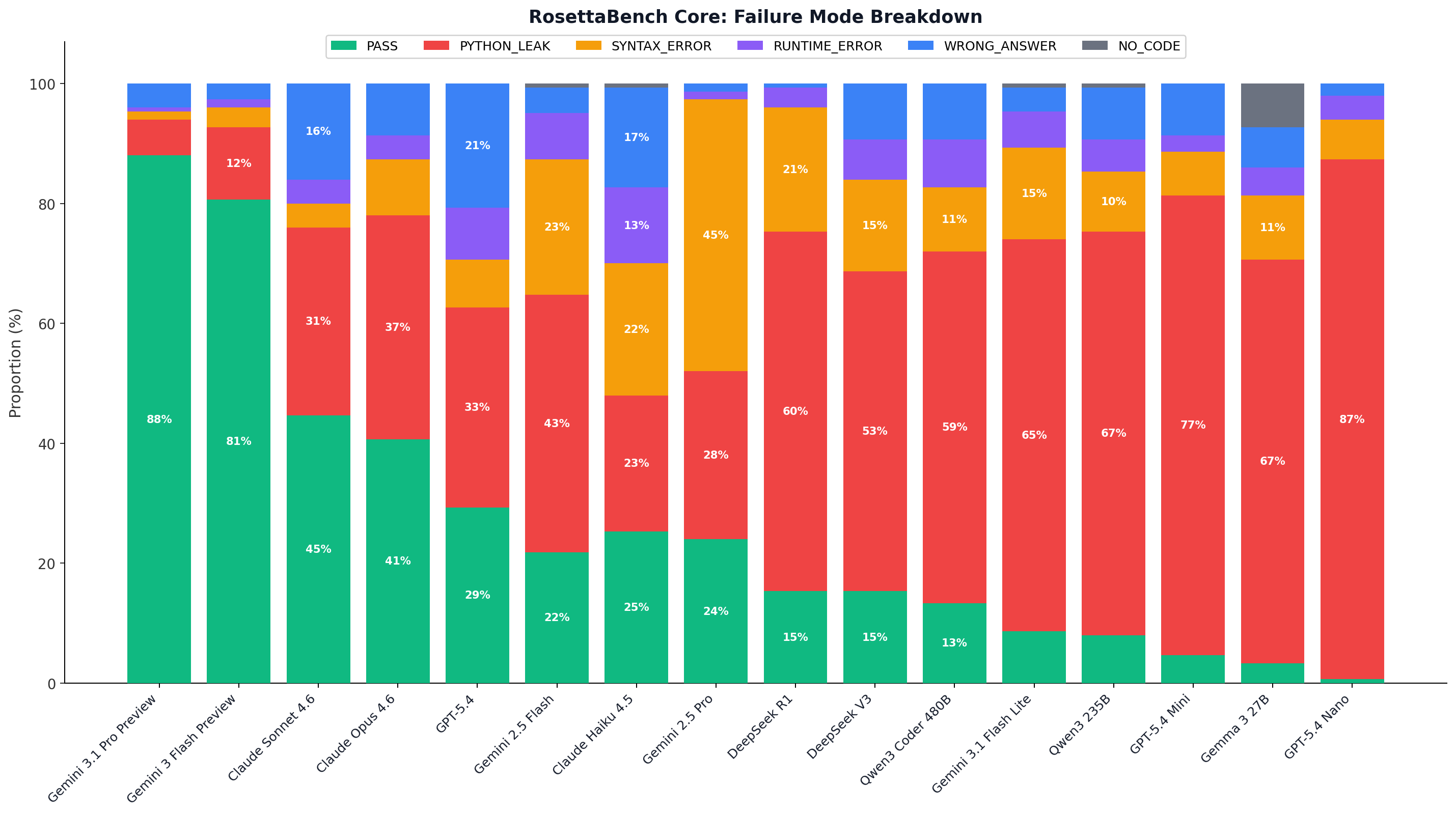
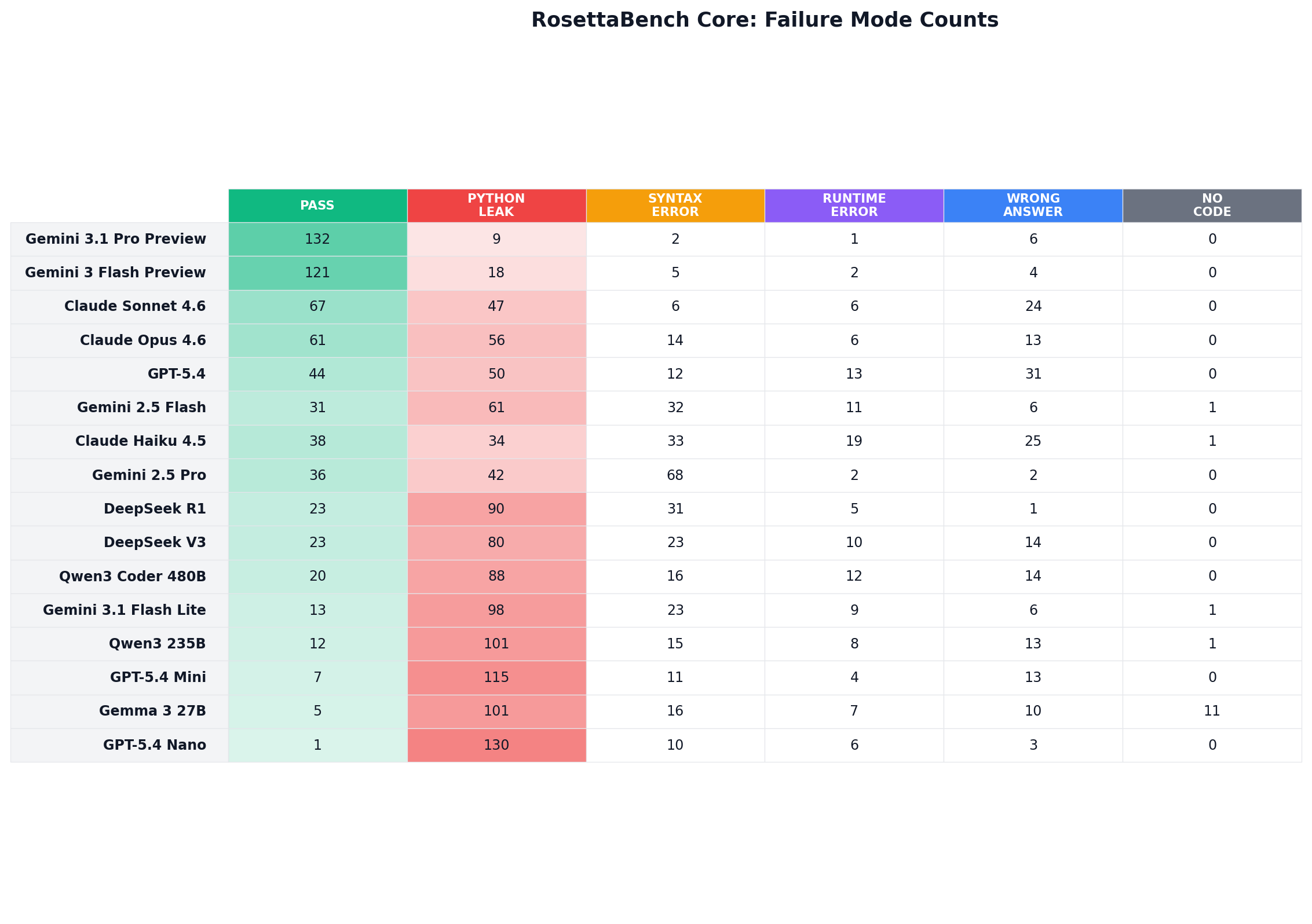
"Memorisers assume. Learners adapt. Problem abc357_b required uppercase conversion, but the few-shot examples only demonstrated .lower(). Every model except Gemini 3.1 Pro Preview and Gemini 3 Flash Preview hallucinated a synthetic .upper() token — reverting to Python muscle memory. The two exceptions used .lower() with a character map, staying within the demonstrated vocabulary."
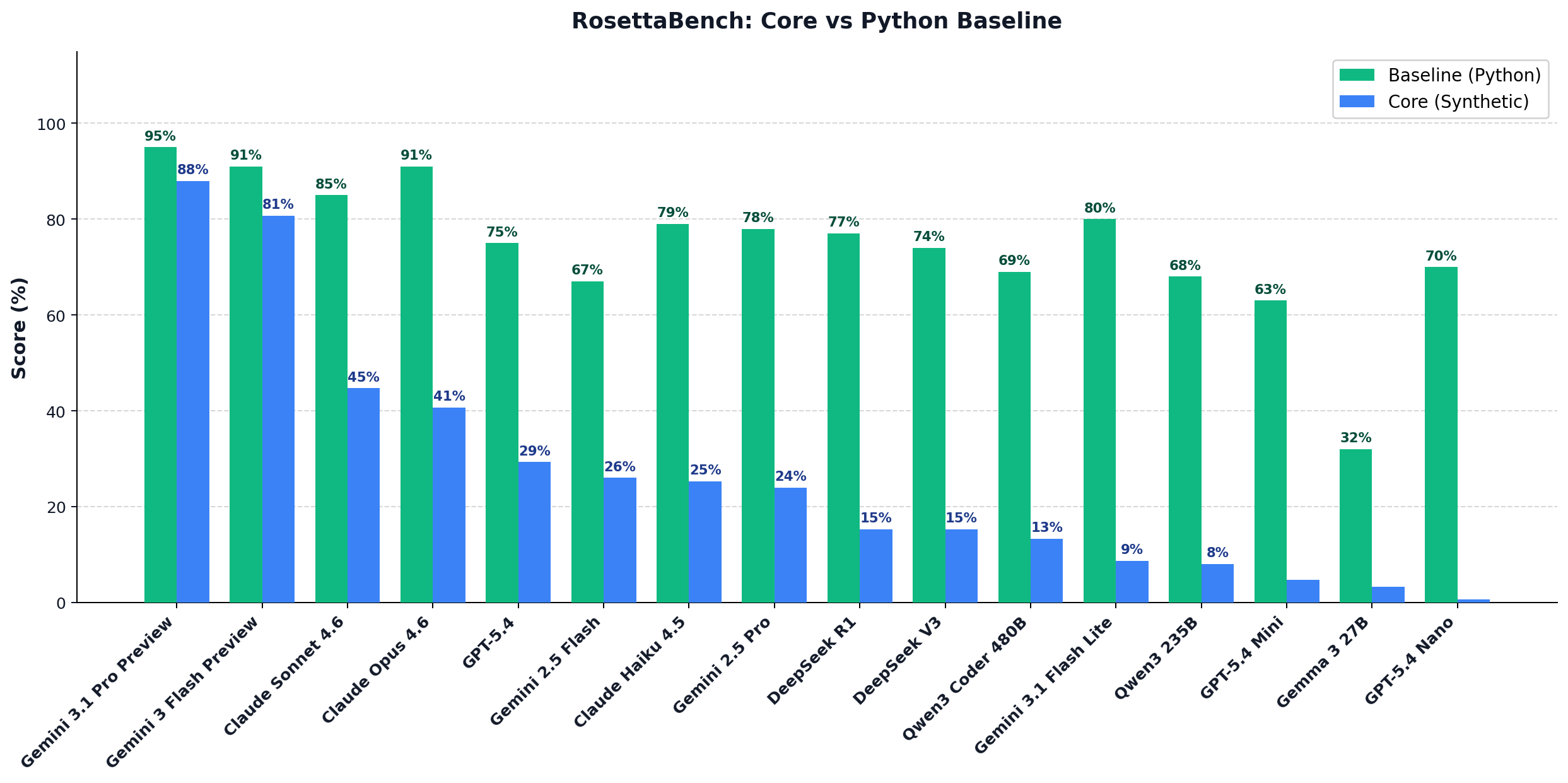
RosettaBench addresses this directly. Each problem is presented in a unique synthetic programming language — a fully remapped variant of Python where all keywords, builtins, methods, operators, and delimiters are replaced with invented, pronounceable tokens: def → spimgleox, if → vraith, print → kroumspor.
No two problems share a language, eliminating cross-problem memorisation. The model receives 6 few-shot example pairs showing the synthetic language alongside its Python equivalent, then must produce a correct solution in the synthetic language.
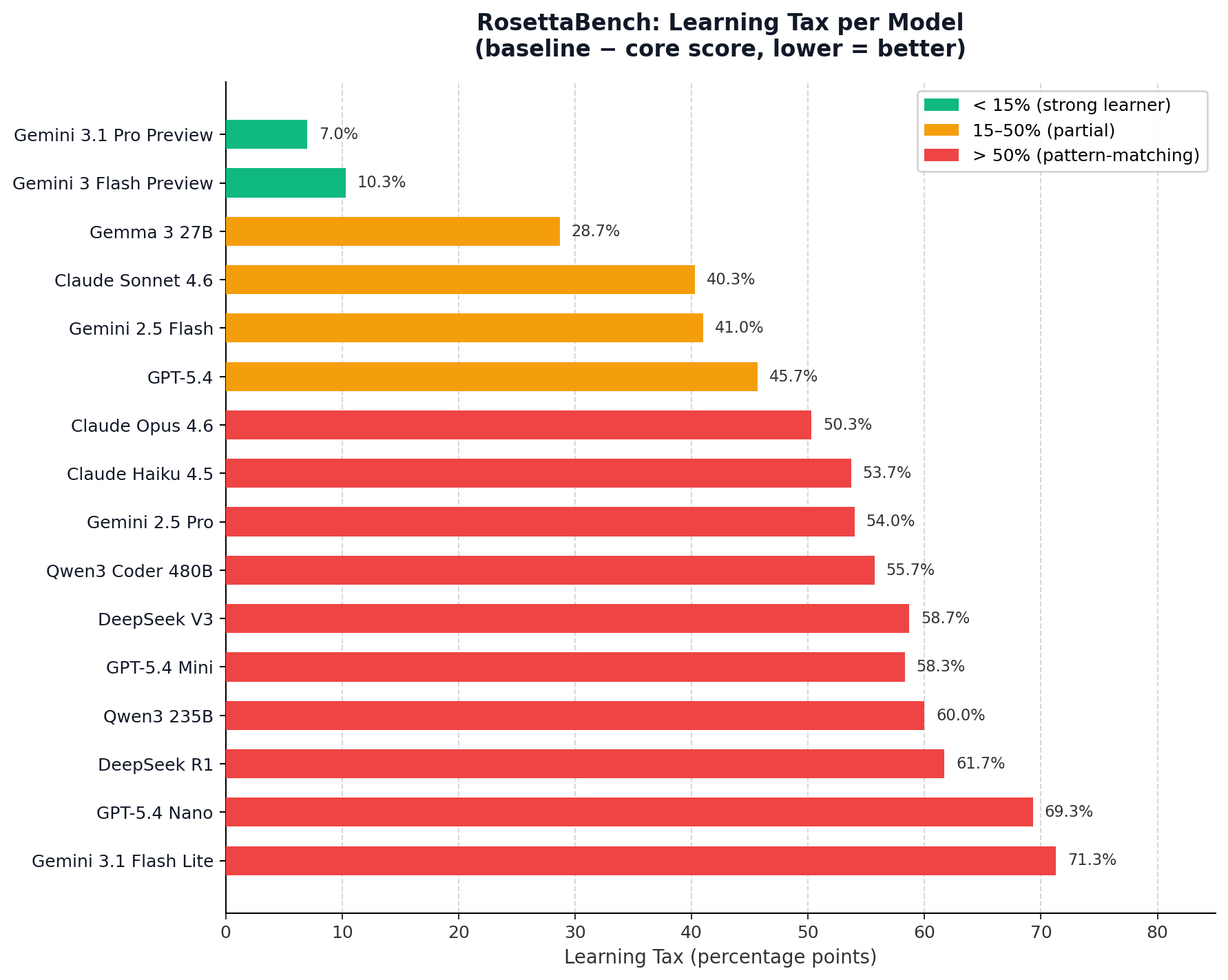
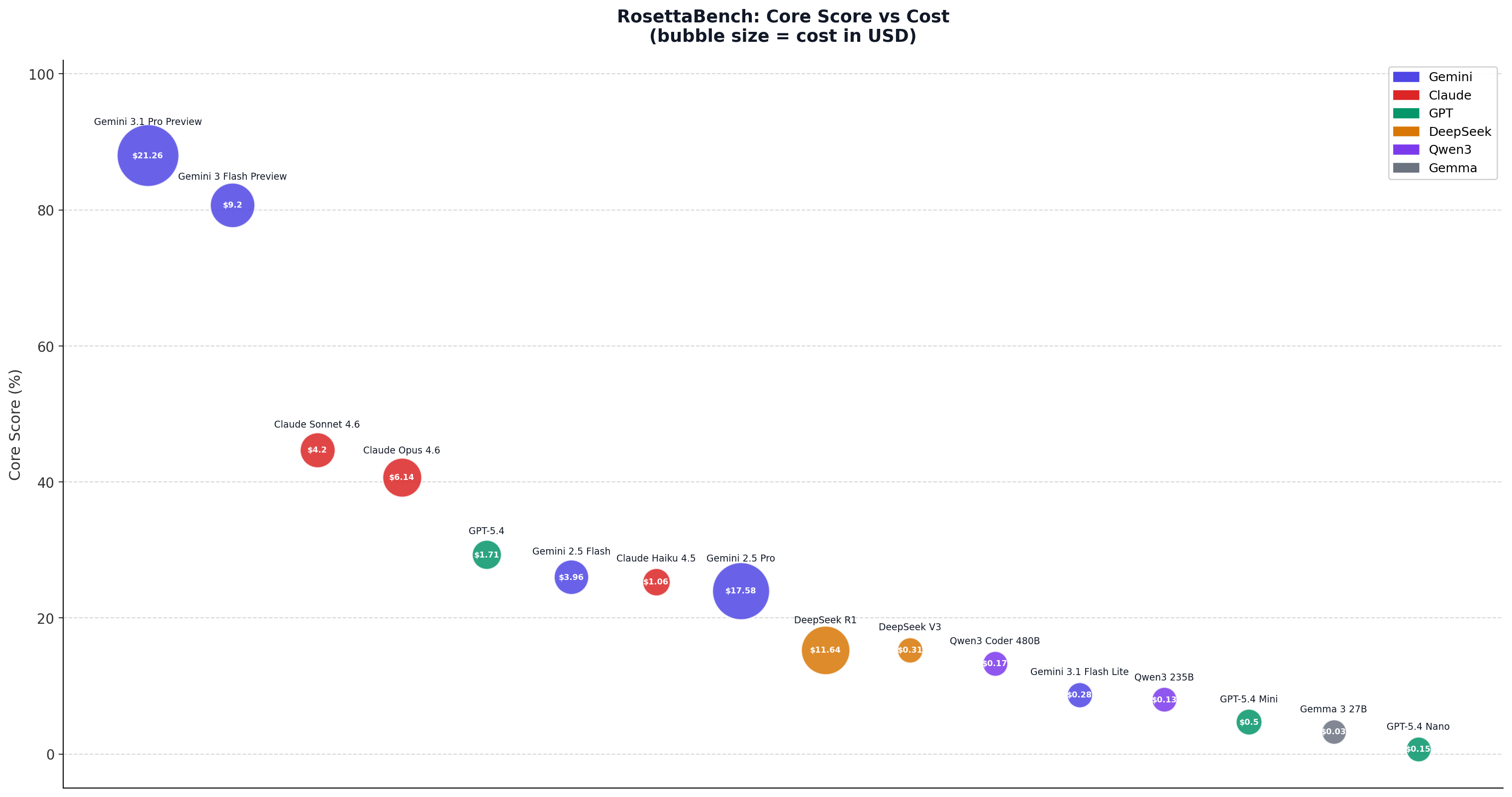
The Learning Tax — defined as baseline score minus core score — quantifies performance loss when familiar Python vocabulary is replaced with a synthetic language. A low learning tax signals genuine in-context language acquisition. A high one signals pre-trained pattern matching.
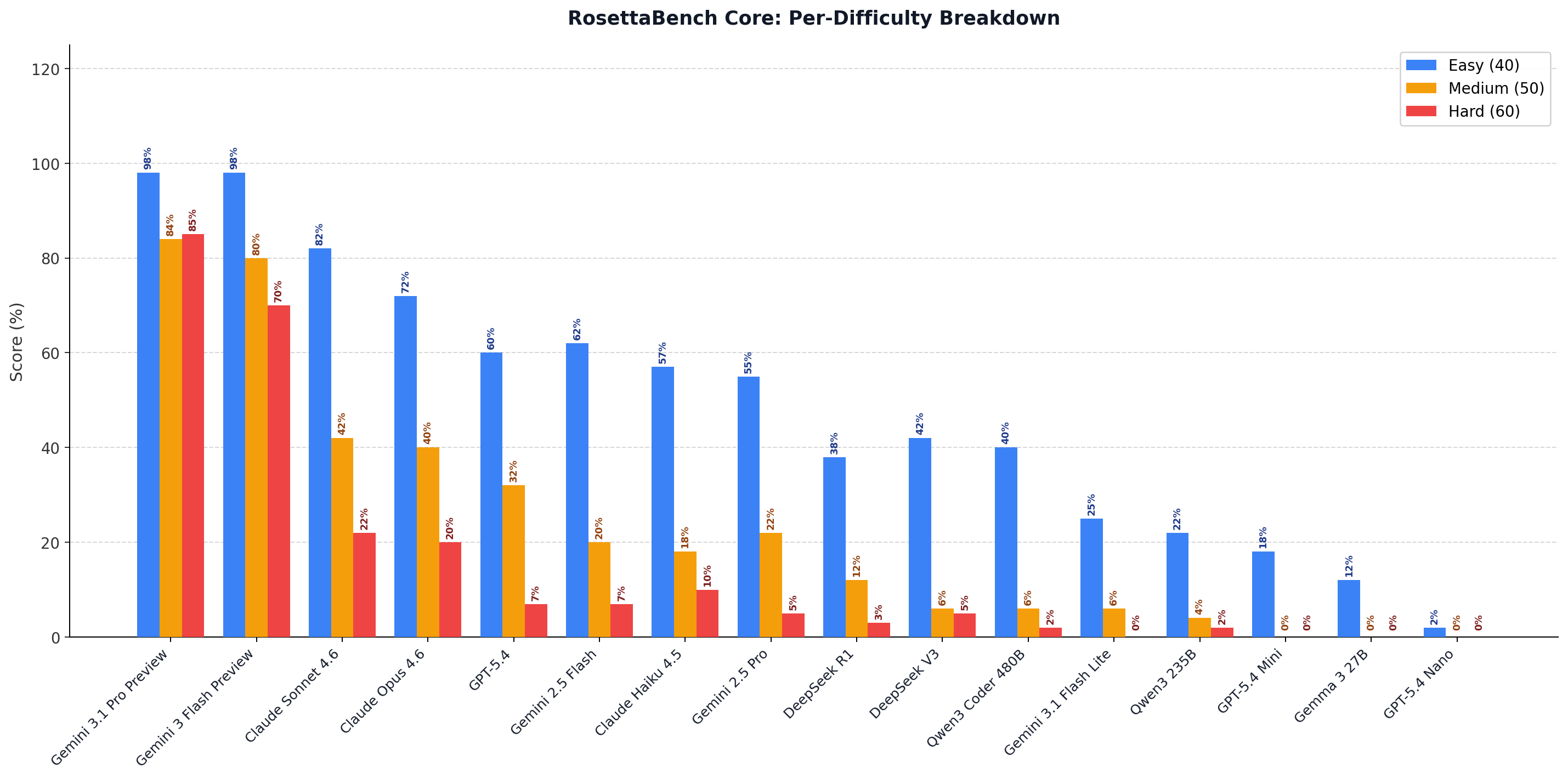
150 AtCoder problems from LiveCodeBench: 40 easy, 50 medium, 60 hard. Only STDIN/STDOUT problems with ≥ 3 test cases. Sampling uses random_state=42; language generation is fully deterministic given a problem seed.